
2025第一单元总结博客 [BUAA-OO]
本文将从笔者自身的角度出发,总结2025年北航面向对象课程第一单元作业(HW1, HW2)的程序设计思路和架构搭建,呈现我在完成一个支持加、减、乘、乘方、三角函数、递推函数、普通函数、求导功能的科学计算器过程中所遇到的问题、思考以及解决方案。
一、架构分析
1.1 项目架构概览
本项目采用面向对象的思想,将化简表达式的总功能划分为了表达式解析部分和合并化简部分,前者对应了Lexer、Paser、FuncManager类,后者对应了Expr、Term、Factor等类,通过对递归下降与正则表达式的结合运用,较好地实现了对表达式的解析与合并化简。
1.2 UML类图

1.3 架构设计
(1) 函数处理与词法分析
FuncManager类:负责处理自定义函数定义与解析,通过HashMap存储函数名、形参与函数表达式,对传入内部的input字符串通过正则表达式进行匹配,并展开递推表达式与普通函数,降低解析表达式时处理函数调用的复杂度。Lexer类:负责对传入的字符串进行词法分析,将表达式字符串分割为一个个的Token,处理连续符号与数字合并,完成储存,方便后续的解析。
(2) 表达式解析
- 通过递归下降法构建了表达式解析器,通过
paserExpr、paserTerm、paserFactor等方法,将表达式字符串解析为Expr、Term、Factor对象,构建表达式树。 Expr、Term、Factor类:分别对应表达式、项、因子,内部用ArrayList存储,方便后续的合并化简操作。- 利用
Factor接口实现多种因子的统一处理,包括NumFactor、PowFactor、FuncFactor、ExprFactor、SinFactor、CosFactor、DerivativeFactor等,分别对应数字、幂、函数、表达式、正弦、余弦、求导因子。
(3) 表达式合并化简
- 通过定义单项式类
Mono与多项式类Poly,将表达式树中的Expr、Term、Factor对象合并为多项式对象,并对其进行合并同类项、化简操作。 Mono类:最终解析得到的基本单元
Poly类:多项式,内部用HashMap存储单项式,在add、mul等方法中实现合并同类项操作。
(4) 统计分析

可以发现,FuncManager类的代码行数最多,原因在于该类需要处理自定义函数的定义与调用,需要处理递推表达式与普通函数,代码量相对较大。并且,笔者在该类中预先对函数进行了部分展开化简(替换定义过的函数、存储递推函数表达式),这虽然不符合递归思想,但大大降低了后续解析表达式的复杂度与成本消耗,提高了解析效率。
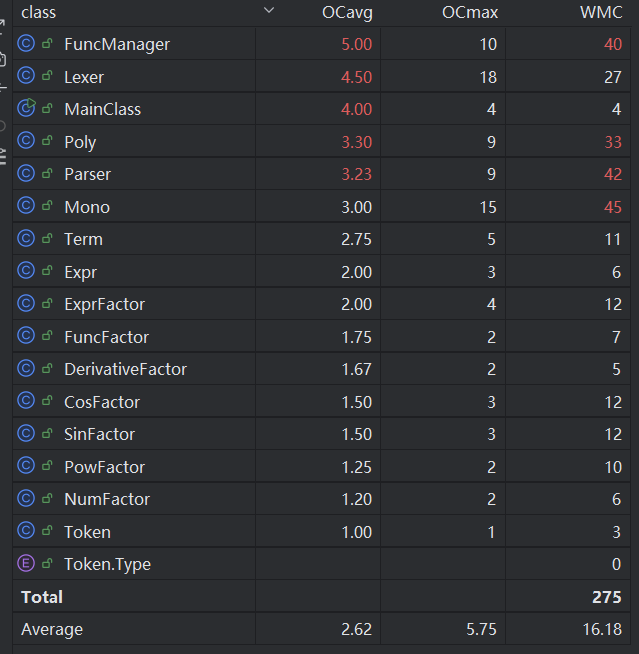
可以发现,类复杂度分布不均,部分核心类承担了较多的复杂逻辑,而一些辅助类或数据类则相对简单。FuncManager、Lexer、Mono、Parser等类的WMC值较高,尤其是Mono类的WMC值高达45,这是因为在toString方法中,需要将多项式对象转换为字符串,而该类中包含了较多的逻辑判断与字符串拼接操作。

Lexer.handleSpecialCharacters()方法复杂度超标的原因是笔者在该方法中实现了对特殊字符的处理,包含了太多if-else判断,导致代码行数与复杂度较高。Mono.toString()和Mono.buildTrigExpr()方法则由于处理基本单元的特判,具有较多的逻辑判断与字符串拼接操作。FuncManager.expandFunction()在递归展开函数时,需要处理递推函数的定义,调用了过多的辅助方法,导致代码行数与复杂度较高。
整个表达式化简项目围绕表达式的解析、因子的封装、多项式的运算与求导展开,各类因子(NumFactor, SinFactor, CosFactor 等)各自聚焦在特定的数学运算逻辑,内聚度相对较好。Parser, Lexer, FuncManager 等在解析层各司其职,但实现细节中个别方法(如 expandFunction、handleSpecialCharacters等)过于复杂,可能需要笔者进一步优化。
二、迭代设计
2.1 第一次作业
(1) 需求分析
第一次作业是对于面向对象与层次化设计的初步尝试,通过实现一个简单的表达式化简程序,来理解面向对象编程的思维方法与设计原则。具体需求如下:
- 实现一个表达式化简程序,能够解析并化简输入的表达式。
- 表达式由若干个项用加减运算连接。
- 项由若干个因子用乘法运算连接。
- 因子可以是常数、幂函数、表达式因子。
- 输出不包含括号的表达式。

(2) 设计思路
通过先导课第七次作业的训练,笔者对于递归下降的解析方法有了一定的了解,而在重温OOpre中的表达式树构建方法并参考了往年博客后,构建了如下架构:
1 | src |
其中,Lexer负责词法分析,将输入字符串解析为Token序列;Parser负责语法解析,Expr, Term, Factor, NumFactor, PowFactor, ExprFactor分别对应表达式、项、因子、常数因子、幂因子、表达式因子;Mono, Poly分别对应单项式与多项式。
程序通过递归下降解析表达式,将解析结果封装成Expr、Term、Factor等对象,再调用Expr.toPoly、Term.toPoly、Factor.toPoly方法递归展开化简为Poly、Mono对象,最后调用Poly.toString、Mono.toString方法生成字符串。
(3) 设计实现
- 词法分析Lexer
Lexer类负责词法分析,将输入字符串解析为基本语法单元Token。nextToken方法从输入字符串中读取下一个Token,并更新当前读取位置。- 第一次作业中,
Lexer类仅支持解析数字、变量、加号、减号、乘号、左括号、右括号、幂运算符等基本语法单元。 - 通过switch-case语句,根据当前读取位置语法单元类型。
1 | // in Token.java |
- 语法解析Parser
Parser类负责语法分析,将Token序列解析为Expr对象。parse方法从Lexer中读取Token序列,并解析为Expr对象。parseExpr、parseTerm、parseFactor方法分别解析表达式、项、因子。parseExpr方法调用parseTerm方法解析项,并将Expr对象的符号传给Term,在此情况下,term之间是加法运算。parseTerm方法调用parseFactor方法解析因子,因子的符号单独解析,factor之间是乘法运算。parseFactor方法解析因子,根据因子类型调用不同的解析方法parseNum、parsePower、parseExprFactor。parseSign辅助方法解析符号,结果传入对象中。
1 | // in Parser.java |
- 表达式展开
- 在
Expr、Term、Factor中添加toPoly方法,按照层次结构展开表达式。 Poly由若干个Mono相加而成,每个Mono是一个基本单元。Mono具有固定形式。- 如此实现了表达式解析存储与计算展开功能的分离,既符合了单一职责原则,也方便调试输出。
- 在
1 | // in Expr.java |
Poly内需要实现
addPoly、multiplyPoly、negPoly方法,分别对应+、*、取反操作,具体实现同样依照层次化结构,依赖addMono方法实现同类项合并。
Mono内需要实现multiply方法,实现系数相乘、指数相加。
- 表达式输出
- 在
Poly中添加toString方法,调用Mono.toString,按照层次结构输出表达式 Mono输出时,需要特判情况以优化输出(第一次的性能分还是好拿的)。
- 在
关于输出优化
主要有两个方向,首先是Poly调用Mono生成的字符串拼接时,将正项放在最前面可以省略+号。其次是在Mono中,如果coe为±1,则省略1;如果exp为0,则省略x,只输出系数;如果exp为1,则省略^1。
(4) 复杂度分析

由于Poly类中循环和特判较多,Lexer类中使用了过多switch-case语句,导致代码复杂度较高,但总体来说,代码结构清晰,符合单一职责原则,每个类只负责一个功能,且每个类的方法也只负责一个功能,符合开闭原则,在后续迭代中,只需要修改解析方法和对应Factor的实现类即可。
2.2 第二次作业
(1) 需求分析

在笔者看来,第二次迭代是本单元跨越难度最大的一次,代码量与架构复杂度都显著上升,引入了新的三角函数因子与自定义递推函数,代码总行数也是来到了近1200行,本次作业的主要需求如下:
- 支持嵌套括号:第一次作业中实现递归下降已经可以支持嵌套括号 ( 慎用正则表达式!)。
- 解析三角函数因子:允许用户输入三角函数因子
sin、cos,最终输出只保留必要括号(难点1:无脑加影响性能,不加形式错误),可以利用三角函数恒等式化简(难点2:化简种类很多,平方和、二倍角、诱导公式等)。 - 支持自定义递推函数:允许用户输入自定义递推函数定义并在表达式中调用,包括初始定义
f{0}、f{1},递推定义f{n}(形参) = 常数*f{n-1}(实参) + 常数*f{n-2}(实参)+表达式,支持在表达式中调用(难点3:如何展开递推定义,如何处理递推定义中的形参与实参,如何降低调用成本防止TLE)。
(2) 设计思路
- 引入函数管理类:新增
FuncManager类,用于管理自定义递推函数,包括存储函数定义、解析展开函数定义、处理函数调用时的换参等。 - 引入函数因子类:新增
FuncFactor类,继承自Factor接口,用于存储函数因子,内部调用FuncManager.callFunc处理函数调用生成对应字符串;调用Parser.parseExpr生成对应Expr对象;重写toPoly方法,调用Expr.toPoly生成对应Poly对象。 - 引入三角函数因子:新增
SinFactor、CosFactor类,继承自Factor接口,用于存储三角函数因子,并重写toPoly方法。 - 修改基本单元Mono类:将基本单元修改为,新增
addSinFactor、addCosFactor方法,用于添加三角函数因子,重写equal与hashCode方法,用于判断Mono对象是否相等。 - 修改多项式Poly类:修改
Poly类中对应方法以兼容新的Mono对象。
(3) 设计实现
- FuncManager类:静态自定义递推函数管理类,功能包括解析存储函数定义、展开递推函数、处理函数调用时的换参等。
- 提供
FuncDefinition方法用于解析初始定义与递推定义,利用正则表达式 + 匹配括号栈函数解析函数名、序号、形参、函数表达式; - 提供
expandFunction方法用于展开递推函数,利用正则 + 递归 + 匹配括号栈函数解析函数表达式中的函数调用,并递归展开; - 提供
callFunc方法用于处理函数调用,利用正则表达式替换处理函数表达式中的函数调用; - 提供
replaceParams辅助方法用于替换函数表达式中的形参; - 提供
findClosingParen与splitParameters辅助方法用于解析递推函数表达式的实参。
- 提供
1 | // in FuncManager.java |
细节实现
注意存储函数时将形参x,y替换成u,v等符号,避免在替换过程出现冲突。解析实参时不能直接用正则表达式,因为实参可能包含无限层次的括号,正则无法处理,需要用栈来匹配括号。为了支持后续可能的迭代(如多种递推函数),我在存储函数表达式时采用了funcName+seq的形式(f对应一个arraylist,存储着每个序号对应的表达式),这在第三次作业中给我带来了一部分的重构,其实完全将funcName保存为"f{n}"的形式会更简洁,也不需要跨越层次,破坏了面向对象的思想。
- 新增因子:本次迭代支持自定义递推函数因子与三角函数因子,笔者增加了三个继承
Factor接口的FuncFactor、SinFactor、CosFactor类以实现层次化结构。FuncFactor类:实现自定义递推函数因子;SinFactor类:实现三角函数因子sin,重写toPoly方法;CosFactor类:实现三角函数因子cos,重写toPoly方法。
1 | // in FuncFactor.java |
-
修改单项式与多项式类:
- 在
Mono类中添加addSinFactor和addCosFactor方法,用于添加三角函数因子,并处理特殊情况(如sin(0)和cos(0)等);添加normalized方法,返回一个经过归一化处理的单项式,将系数视为1,作为Poly类的Mono哈希表中的键;重写equal和hashCode方法,确保归一化后的单项式可以正确比较与生成哈希码;修改multiply方法与toString方法,以适应三角函数因子的处理; - 在
Poly类中添加negateTriFactor方法,判断指数最高项符号是否为负,使三角函数因子内Poly的符号一致,便于合并同类项;重写了equal和hashCode方法,确保归一化后的多项式可以正确比较合并;修改了原先的addMono方法,使其在添加单项式之前先进行归一化处理作为哈希表中的键,修改了toString方法,以适应三角函数因子的处理。
- 在
-
修改表达式解析:
- 在
Lexer类中增加了对函数、三角因子的识别,添加了对应的token类型; - 在
Parser类中添加parseFuncFactor、parseSinFactor、parseCosFactor方法,用于解析自定义函数因子与三角函数因子,返回Factor对象;修改parseFactor方法,支持以上因子解析; - 在
MainClass类中,添加对递推函数定义的处理;
- 在
关于性能优化
这次作业我只处理了最基本的三角函数特殊值与括号问题,对于三角函数的平方和二倍角等公式并没有处理,因此性能上还有较大优化空间,这也导致我的性能分数并不高,但我在互测中的hack成功次数较多,参见bug分析部分。
(4) 复杂度分析

函数管理类FunctionManager负责管理函数,包括函数的添加、展开、存储、查找、调用等操作,因此其内部方法数量较多且循环调用,依赖较强,因而其复杂度较高,通过静态实现,避免了每次调用时创建对象的开销,提高了效率。Lexer类由于要进行if-else判断,复杂度较高在所难免。Parser类负责解析表达式,由于新增因子后方法较多且需要较多判断语句,因此其复杂度较高。Poly类负责多项式的存储与合并,包含很多循环判断语句,复杂度较高。但整体而言,由于新增因子后方法数量增加,复杂度有所提高,但整体的层次化设计使得代码结构更加清晰,易于维护和扩展。
2.3 第三次作业
(1) 需求分析与思路

要求实现普通自定义函数与求导功能,整体难度较低,主要在于对普通自定义函数的解析与求导因子的处理:
- 普通自定义函数:在静态函数管理类
FunctionManager中添加对应方法,用于处理普通自定义函数定义和解析,存储函数名、函数表达式、形参; - 求导因子:添加
DerivativeFactor类,用于处理求导因子,包括求导因子的toPoly方法和toDerivative方法,分别用于将求导因子转换为多项式和求导因子求导; - 求导:在
Expr、Term、Factor类中按照求导公式添加求导方法,分别用于表达式、项、因子的求导,返回求导后的多项式。

(2) 设计思路与实现
- 支持普通自定义函数:普通自定义函数的定义处理与解析可完全类比于递推函数,在
FunctionManager类中修改funcDefinition方法,添加对普通自定义函数的定义处理即可,但对于嵌套的普通函数(如h(x)=g(g(x))),笔者选择在定义之初就将其展开,避免后续调用时出现递归调用的问题,因此新增了expandNormalFunction方法,用于递归展开普通自定义函数,直到其中不再包含普通自定义函数为止;同样在自定义递推函数表达式中,同样可能出现嵌套的普通函数,只要调用该方法即可; - 求导因子:求导因子处理较为简单,只需新增
DerivativeFactor类并添加toPoly和toDerivative方法即可,其中toPoly方法较为简单,只需调用内部表达式expr的toDerivative方法即可,toDerivative方法则较为复杂,需要先将内部的表达式expr求导,然后再toString,重新解析成求导后的表达式expr',再调用expr'的toDerivative方法。似乎有点绕而且影响性能?笔者于是为每个数据类增加了一个polyCache属性,用于缓存求导后的多项式,避免了重复toPoly(尤其是求导的乘法法则); - 求导方法:笔者依然根据递归下降原则,为每个数据类增加了
toDerivative方法,用于求导,返回求导后的多项式;
1 | //in Expr.java |
(3) 复杂度分析
本次作业后得到了完整架构,具体分析见开头,此处不再赘述。
关于重构与整体架构
在三次迭代作业中,我的主体架构在第一次作业中就已确定下来,即使用词法分析和语法解析,将输入的表达式字符串递归解析成表达式、项、因子对象,随后同样遵循递归下降原则,层次化调用toPoly方法,将表达式对象转换成多项式对象。在迭代过程中,我在实现需求时不可避免地对部分代码进行了重构,但主要关注于方法的拓展与兼容性,这也让我的程序没有出现太多由于重构而导致的bug。
三、Bug分析
第一次作业:
- 笔者在第一次作业的强测和互测中未出现bug,这为后续的迭代作业打下了较好的基础。
第二次作业:
- 第二次作业笔者出现了两处bug,均出现在复杂度较高的
Mono类中,具体如下:- 第一处是关于
sin(0)^0的结果出错,笔者在Mono.addSinFactor方法中,将sin因子添加到基本单元中时,没有首先特判指数为0的情况,导致sin(0)^0由于解析三角函数因子内部的Poly对象为0,根据sin(0)=0使得最终结果为0,而不是1。修复bug时只要在addSinFactor方法中特判指数为0的情况即可(bug所在方法的复杂度并不高)。
1
2
3
4
5
6
7
8
9
10
11
12public void addSinFactor(Poly factor, BigInteger exponent) {
<-- bug: 没有特判指数为0直接返回
//if (exponent.equals(BigInteger.ZERO)) {
// return;// 特判指数为0的情况
//}
if (factor.toString().equals("0")) {
this.coefficient = BigInteger.ZERO;
} else if (factor.negateTriFactor()) {
Poly negFactor = factor.negPoly(factor);
...
}
}- 第二处bug出现在
Mono.buildTrigExpr方法中,该方法主要用于特判三角函数因子内添加必要括号。笔者在buildTrigExpr方法中,使用了大量if-else判断语句,以实现要求的三角函数对应的嵌套因子为不带指数的表达式因子时,该表达式因子两侧必要的一层括号,笔者绘制了分类树,将所有情况分类处理,但仍然由于归一化生成哈希表键值对和条件判断内容不清的问题,出现了会在诸如sin(2*x^2)的情况下,少输出一层括号,导致了强测两个点正确性的丢失以及互测时多个hack()。该方法的圈复杂度为25,由于涉及if-else特判导致复杂度高,笔者在每一次特判时都加了注释(),结果还是出现了bug :innocent:。说明注释不能代替思考,代码也要正确!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21private String buildTrigExpr(String trigName, Poly poly) {
// 如果多项式只有一个单项式,则做细分判断
if (poly.getMonos().size() == 1) {
Mono onlyMono = poly.getMonos().keySet().iterator().next();
BigInteger coe = onlyMono.getCoefficient(); <-- bug: 系数始终为1
// onlyMono是归一化后系数为1的单项式,所以得到的coe始终为1
// 这导致后续判断是否要加括号时,无法正确识别到单项式前的系数
// 应该修改为 coe = poly.getMonos().get(onlyMono);
BigInteger exp = onlyMono.getExponent();
// 三角函数因子数量(如 > 1 则视为较复杂表达式)
int trigCount = onlyMono.getSinMap().size()
+ onlyMono.getCosMap().size();
...
}
...
// 3a) 指数为 0
if (exp.equals(BigInteger.ZERO)) { <-- bug: 没有判断三角因子个数
// 应修改为 exp.equals(BigInteger.ZERO) && trigCount == 0
return trigName + "(" + poly.toString() + ")";
}
} - 第一处是关于
第三次作业:
- 在本次作业强测与互测中,笔者没有发现bug。
四、测试与互测
第一次作业:
- 笔者根据递归下降分析法的思想,使用python编写了数据生成器,利用
python.sympy库的化简结果与程序输出结果比对,搭建了自动评测机,但并未找出房间内同学的bug
第二次作业:
- 笔者在第一次作业搭建的评测机基础上修改了数据生成器,但hack成功率却不甚理想,于是手搓了大量极端数据在本地进行测试,比对房间内所有程序的输出,成功hack了11次。
- 在本地测试平方和二倍角化简相关数据时,笔者注意到某些同学的输出时间较长,在阅读其
Poly类代码时发现了大量嵌套的for循环和if判断,利用好室友给的TLE数据成功hack了几位同学。1
2
3
4
51
f{n}(x)=1*f{n-1}(sin(sin(sin(x))))+0*f{n-2}(x)
f{1}(x)=sin(sin(sin(sin(x))))
f{0}(x)=sin(sin(sin(sin(x))))
f{5}(f{0}(f{0}(f{0}(f{0}(f{0}(f{0}(x)))))))
第三次作业:
- 笔者在第二次作业的基础上修改了数据生成器,利用全自动评测机进行代码的本地测试与互测对拍,成功hack其他同学8次。下次一定继续写评测机!第三次作业互测对于cost限制比较严格,所以没有从TLE数据入手(这种数据有点太邪恶了 bushi)
综上所述,hack过程最好应当是自动评测机+手搓极端数据+结合代码构造数据,实现“多方位全天候hack攻击”(bushi)。
在笔者看来,在有时间的情况下,直接阅读其他同学的代码会比盲目构造数据具有更大收获,这不仅仅是找出别人的bug,更是学习其他优秀代码的宝贵机会,例如,笔者注意到,部分同学会在一个类中提供多种初始化方法,这样的好处是可以在初始化时选择不同的数据结构,从而优化代码性能,这种思想就非常值得借鉴。
五、优化分析
笔者对于三角函数的优化并不多,甚至可以说是几乎没有,这让笔者在避免被TLE数据攻击的同时,也失去了很大一部分性能分,笔者第三次作业中的强测得到了92.7分,全部是由于性能分的丢失。对于平方和与二倍角化简的处理,如果盲目嵌套多层for循环,非常影响复杂度与运行速度,对此笔者想出的解决方法是,为所有数据类都增加polyCache和polyDirty属性,减少非必要的toPoly方法调用,不用担心TLE。
六、心得体会
总结博客写了这么长,终于能跳出代码,谈谈我的学习体会了。编程与代码能力的提升最重要的是动手实践,OO课程通过先导课冒险小游戏 的开发和第一单元对于递归下降和层次化设计的学习,让我在实践中掌握理论,这对于CS课程的学习是非常有益的。试想去年以前,笔者的最长程序还是几百行代码的数据结构大作业,而到今天,通过三次迭代开发,已经能够完成一个功能较为完善的程序,这无疑是一大进步。诚然,第一单元的迭代作业具有一定的难度,笔者也在此过程中遇到了不少问题,也还有一些遗憾(比如三角函数的优化),但正是思考钻研这些问题,我对于面向对象设计与构造的理解也不断进步,不断成长。当然,笔者也意识到,编程之路还很长,还有许多需要学习的地方,例如抽象层次和递归。常常说,人理解循环,神理解递归。 递归是神的语言,这可能是因为,人的生命只有一次,所以理解不了生命反复。(突然感慨)
七、一些建议
- 建议cost的计算可以给得明确一些(能够提供计算器就更好了),和室友的好几次hack互测结束被收回了:sob:。第三次迭代cost限制严格,根本不想构造TLE数据(担心又会成功提交非法数据)。






![2025 年数据库大作业 [BUAA-DB]](http://gitee.com/TheUHO/blog/raw/master/images/202407212255287.jpg)
![2026年算法设计与分析期末回忆版[BUAA-算法]](https://gitee.com/TheUHO/blog/raw/master/images/202407212255294.jpg)
![2025年春本科生机器学习期末回忆版[BUAA-ML]](https://gitee.com/TheUHO/blog/raw/master/images/202407212255291.jpg)